
Current Projects (Group Böhm)
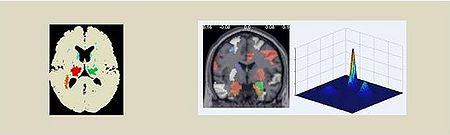
Multimodal Data Mining to analyze brain functions in state of rest
| Period: | 2008-2015 |
| Funding: | Clinic 'Rechts der Isar' Technical University of Munich, department for neuroradiology |
The spontaneous brain activity in the state of rest has been explored insufficiently. The image generating methods, e.g. EEG and fMRI, provide information on the intrinsic brain activity i.e. they demonstrate the interaction of the brain areas within various networks that are characterized by exalted reciprocal functional connectivity. First findings demonstrate that psychiatrical and neurological pathologies like Alzheimer's disease and depressions modify the complex interactions of these networks. The current project is aimed at the development of a data-mining technique that should analyse the static data obtained through various imaging procedures. The project's framework applies and develops the clustering and data-mining methods.

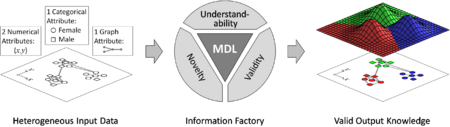
iKDD: Integrative Knowledge Discovery to Explore Complex Biological Systems
| Period: | 2013-2019 |
| Funding: | Cooperative Project with HMGU |
We are drowning in data but starving for information. Especially for data-intensive life sciences, biology and medicine, the data explosion is both, a blessing and a curse. What is information? In contrast to supervised data mining methods like classification or regression, an explorative data analysis is potentially producing any kind of regularities and patterns which are derivable from the data. With exploration techniques like clustering, outlier detection, association rule mining, or dimensionality reduction, explorative data analysis has a long history and has achieved a high level of maturity. However, the community agrees that there are among others two major open challenges to be addressed in the near future: (1) A unifying theory considering the isolated exploration methods in a larger context, and (2) data integration considering a wide range of simple (numerical, categorical) and complex (graph, tree) data types as input and output of data analysis. We address both challenges regarding by every explorative data analysis technique as an information factory processing massive volumes of heterogeneous input data and producing condensed and interesting output information. Elements from information theory allow us to comprehensively analyze and quantify different quality aspects of the output information, including compression rate, novelty and validity and therefore contribute towards a better understanding of what information truly is. This novel, powerful and very general view of explorative data mining allows us to develop a unifying theory covering a wide range of algorithms like clustering, outlier detection, dimensionality reduction on an unprecedented variety of attribute types working as input and output.

Clustering algorithms for the analysis of Diffusion Tensor Images (DTI)
| Period: | 2008-2014 |
| Funding: | Chinese Scholarship Council (CSC); DAAD |
Understanding the human brain connectivity is an elusive goal for neuroscience due to its complex and the limitation of technologies in past several centuries, especially for the anatomical connectivity. Currently, the emergence of related DTI technologies offer a promising way to explore the anatomical pattern in vivo. This project aims to understand the brain connectivity using related data mining techniques. The key objectives are as follows:
- Automatically clustering the 3D white matter tracts;
- Quantitative analysis of fiber bundles with different groups;
- Investigating the relationship between structural connectivity and functional connectivity.


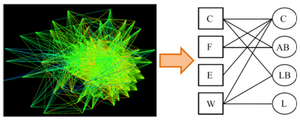
Information-theoretic Graph Mining
| Period: | 2010-2014 |
| Funding: | Chinese Scholarship Council (CSC) |
Many applications produce large amounts of graph- structured data consider e.g. protein-protein interaction networks. In this project, we aim at discovering the major patterns from graphs using an information-theoretic approach: Patterns like clusters or structure primitives like transitive triangular link patterns allow us to effectively compress the original massive graph. Thereby, the underlying structure and generation rules become evident.

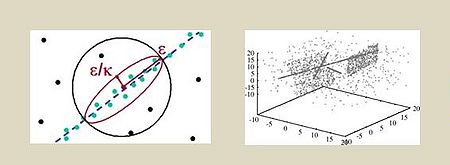
Data mining solutions for subspaces of high dimensional data
| Period | 2010-2014 |
| Funding | Chinese Scholarship Council (CSC) |
In the semi-automatic analysis using data mining methods like clustering following problems emerge: Many features are measured or collected automatically but are irrelevant for particular data mining approaches as these can be noisy or redundant. As in real data typically different sets of features are relevant for different groups of objects methods for reducing the feature space do not necessary lead to satisfactory results. For this reason development and analysis of methods for subspace or correlation clustering is needed to individually and flexiblly scale high-dimensional feature spaces to low dimensions. The aim of the project was to develp innovative data mining methods for high-dimensional feature spaces.

Former Projects (Group Böhm)
BioKeyS - Pilot-DB - Teil 2
| Period: | 2009-2010 |
| Funding: | Federal Office for Information Security (BSI) |
There exist various indexing structures for an efficient similarity search in large databases. Objects are represented as one or multiple vectors or through a probability density function. The goal of this project is to extend our existing index structures for an efficient similarity search for different biometric approaches and to guarantee a secure storage of the data in the index structure. Therefore cryptographic techniques have to be incorporated to avoid a reconstruction of the stored biometric data through an invader who can fully access the whole database. This can be achieved by a secure one-way function that encrypts all security relevant data. The challenge of this project is to ensure that this one-way function doesn`t have any impact neither on effectivity of biometric identification or authentification nor on efficiency of similarity search. The fingerprint identification is based on their minutiae that are ends and bifurcations of the epidermal ridges. The task is to develop an efficient matching algorithm in combination with an indexing structure.
For more information please visit the BSI website.


Efficient search in uncertain data by the use of index structures for probability density functions
| Period: | 2008 - 2010 |
| Funding: | German Research Foundation (DFG) |
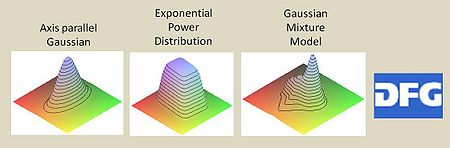
The well-established procedure for modelling uncertain data is to assign probability density functions to the objects. For this purpose, most of the existing approaches only use a relatively simple model, namely axis parallel Gaussians. In this project, we define a very general notion for modelling the uncertainty, based on Exponential Power Distributions and Gaussian Mixture Models. In addition, we want to develop suitable index structures. For this project we identified a wide application field ranging from image search over medicine to biometrics.

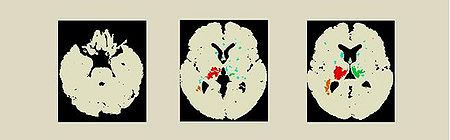
Multi-centric classification of Alzheimer's disease in magnetic resonance images
| Period: | 2010 |
| Funding: | Clinic and Policlinic for psychiatry and psychotherapy of the University of Munich |
As clinical studies are often highly expensive and time-consuming multi-centric studies exhibit a good alternative to get a representative set of data. However, the data of different clinical centers are generated under different clinical conditions which is challenging to an algorithmic analysis. We propose a data mining framework to automatically discriminate between patients with Alzheimer's disease (AD) or mild cognitive impairment (MCI) and elderly controls (HC) based on magnetic resonance images (MRI).


Software: JGrid/FCC
Detection of spatial patterns of atrophy in Alzheimer's disease from structural MRI
| Period: | 2007 - 2008 |
| Funding: | Clinic and Policlinic for psychiatry and psychotherapy of the University of Munich |
Magnetic resonance imaging (MRI) allows to display brain structures with highest resolution. To fully exploit the potential of this imagining modality, data mining methods are required to identify subtle differences in brain structure caused by disorders such as Mild Cognitive Impairment and early stage Alzheimers disease. We proposed a data mining framework which combines elements from feature selection, clustering, classification and provides a concise visualization of affected areas in the brain.

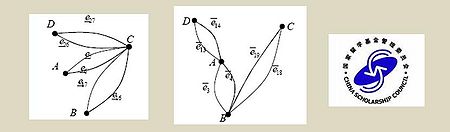
Temporal Graph-Mining based on the Rough Graph Theory
| Period: | 2007-2008 |
| Funding: | Chinese Scholarship Council (CSC) |
In this project we combined the Rough Graph Theory and the idea of Markov Chains to model dynamic systems, like metabolic pathways, intra-cellular signal cascades or activation-profiles of the human brain. Within the scope of this project, we aimed to support the semi-automatic detection of such systems by an interactive data mining process.

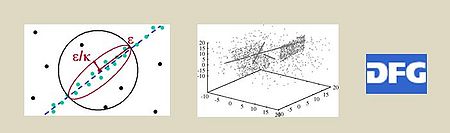
Efficient and effective data mining solutions for high dimensional data
| Period | 2006-2008 |
| Funding | German Research Foundation (DFG) |
Increasing automation and networking of the modern information society leads to an increase volume of data as well as complexity of the data. Therefore in the semi-automatic analysis using data mining methods like clustering following problems emerge: Many features are measured or collected automatically but are irrelevant for particular data mining approaches as these can be noisy or redundant. As in real data typically different sets of features are relevant for different groups of objects methods for reducing the feature space do not necessary lead to satisfactory results. For this reason development and analysis of methods for subspace or correlation clustering is needed to individually and flexiblly scale high-dimensional feature spaces to low dimensions. The aim of the project was to develp innovative data mining methods for high-dimensional feature spaces.

Data Mining in biomedical data
| Period: | 2003-2006 |
| Funding: | Austrian Research Promotion Agency (FFG) |
| Health Information Technologies Tirol | |
| Partner: | Biocrates Life Science GmbH, Innsbruck, Austria |
| Medical University Innsbruck, Department for paediatrics and adolescent medicine |
In the context of this project, we developed a classification model for newborns that suffer from Phenylketonuria (PKU), an autosomal recessive genetic disorder. For this purpose, we only used parameters of metabolic pathways (amino acids) that are determined by mass spectrometry. Further optimizations were achieved by feature selection and reduction of the dimensionality (e.g. by PCA) of the feature space. In contrast to a "golden standard" data set, we obtained values for sensitivity and selectivity of more than 99%.


